
Large Language Models
Large Language Models (LLMs) are trained on massive amounts of text data. As a result, they can generate coherent and fluent text. LLMs perform well on various natural languages processing tasks, such as language translation, text summarization, and conversational agents. LLMs perform so well because they are pre-trained on a large corpus of text data and can be fine-tuned for specific tasks. GPT is an example of a Large Language Model. These models are called “large” because they have billions of parameters that shape their responses. For instance, GPT-3, the largest version of GPT, has 175 billion parameters and was trained on a massive corpus of text data.
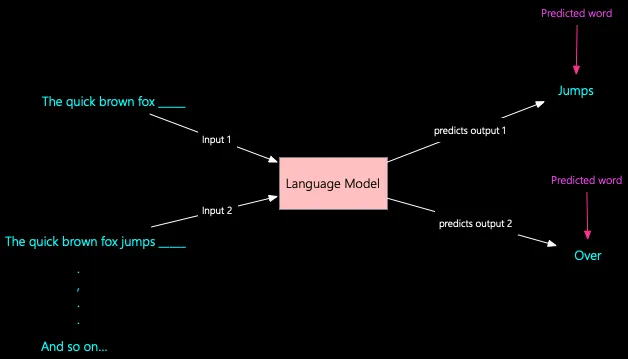
The basic premise of a language model is its ability to predict the next word or sub-word (called tokens) based on the text it has observed so far. To better understand this, let’s look at an example.
Transformer Architecture: The Building Block of Large Language Models
The transformer architecture is the fundamental building block of all Language Models with Transformers (LLMs). The transformer architecture was introduced in the paper Attention is all you need, published in December 2017. The simplified version of the Transformer Architecture looks like this:
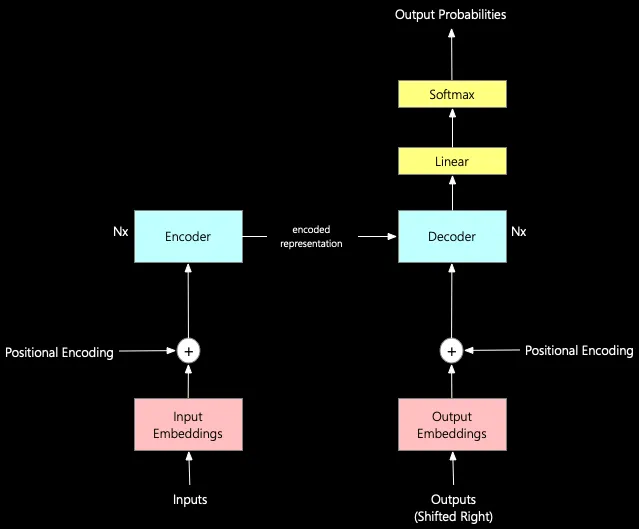
There are seven important components in transformer architecture. Let’s go through each of these components and understand what they do in a simplified manner:
-
Input Embedding: The tokens entered by the user are considered inputs for the machine learning models. However, models only understand numbers, not text, so these inputs need to be converted into a numerical format called "input embeddings". Input embeddings represent words as numbers, which machine learning models can then process. These embeddings are like a dictionary that helps the model understand the meaning of words by placing them in a mathematical space where similar words are located near each other. During training, the model learns how to create these embeddings so that similar vectors represent words with similar meanings.
-
Positional Encoding: In natural language processing, the order of words in a sentence is crucial for determining the sentence’s meaning. However, traditional machine learning models, such as neural networks, do not inherently understand the order of inputs. To address this challenge, positional encoding can be used to encode the position of each word in the input sequence as a set of numbers. These numbers can be fed into the Transformer model, along with the input embeddings. By incorporating positional encoding into the Transformer architecture, GPT can more effectively understand the order of words in a sentence and generate grammatically correct and semantically meaningful output.
-
Encoder: The encoder is part of the neural network that processes the input text and generates a series of hidden states that capture the meaning and context of the text. The encoder in GPT first tokenize the input text into a sequence of tokens, such as individual words or sub-words. It then applies a series of self-attention layers; think of it as voodoo magic to generate a series of hidden states that represent the input text at different levels of abstraction. Multiple layers of the encoder are used in the transformer.
-
Outputs (Shifted Right): During training, the decoder learns how to guess the next word by looking at the words before it. To do this, we move the output sequence over one spot to the right. That way, the decoder can only use the previous words. With GPT, we train it on a ton of text data, which helps it make sense when it writes. The biggest version, GPT-3, has 175 billion parameters and was trained on a massive amount of text data. Some text corpora we used to train GPT include the Common Crawl web corpus, the BooksCorpus dataset, and the English Wikipedia. These corpora have billions of words and sentences, so GPT has a lot of language data to learn from.
-
Output Embedding: Models can only understand numbers, not text, like input embeddings. So the output must be changed to a numerical format, known as “output embeddings.” Output embeddings are similar to input embeddings and go through positional encoding, which helps the model understand the order of words in a sentence. A loss function is used in machine learning, which measures the difference between a model’s predictions and the actual target values. The loss function is particularly important for complex models like GPT language models. The loss function adjusts some parts of the model to improve accuracy by reducing the difference between predictions and targets. The adjustment ultimately improves the model’s overall performance, which is great! Output embeddings are used during both training and inference in GPT. During training, they compute the loss function and update the model parameters. During inference, they generate the output text by mapping the model’s predicted probabilities of each token to the corresponding token in the vocabulary.
-
Decoder: The positionally encoded input representation and the positionally encoded output embeddings go through the decoder. The decoder is part of the model that generates the output sequence based on the encoded input sequence. During training, the decoder learns how to guess the next word by looking at the words before it. The decoder in GPT generates natural language text based on the input sequence and the context learned by the encoder. Like an encoder, multiple layers of decoders are used in the transformer.
-
Linear Layer and Softmax: After the decoder produces the output embeddings, the linear layer maps them to a higher-dimensional space. This step is necessary to transform the output embeddings into the original input space. Then, we use the softmax function to generate a probability distribution for each output token in the vocabulary, enabling us to generate output tokens with probabilities.
The Concept of Attention Mechanism
Attentions is all you need. - Vaswani et al.
The transformer architecture beats out other ones like Recurrent Neural networks (RNNs) or Long short-term memory (LSTMs) for natural language processing. The reason for the superior performance is mainly because of the attention mechanism concept that the transformer uses. The attention mechanism lets the model focus on different parts of the input sequence when making each output token.
-
Parallelism: The RNNs don’t bother with an attention mechanism. Instead, they just plow through the input one word at a time. On the other hand, Transformers can handle the whole input simultaneously. Handling the entire input sequence, all at once, means Transformers do the job faster and can handle more complicated connections between words in the input sequence.
-
Long-range dependencies: LSTMs use a hidden state to remember what happened in the past. Still, they can struggle to learn when there are too many layers (a.k.a. the vanishing gradient problem). Meanwhile, Transformers perform better because they can look at all the input and output words simultaneously and figure out how they’re related (thanks to their fancy attention mechanism). Thanks to the attention mechanism, they’re really good at understanding long-term connections between words.
Let’s summarize:
- It lets the model selectively focus on different parts of the input sequence instead of treating everything the same way.
- It can capture relationships between inputs far away from each other in the sequence, which is helpful for natural language tasks.
- It needs fewer parameters to model long-term dependencies since it only has to pay attention to the inputs that matter.
- It’s really good at handling inputs of different lengths since it can adjust its attention based on the sequence length.