

Text Preprocessing
Text preprocessing in Transformer models is a bit different from traditional machine learning models. In traditional machine learning models, we use techniques like stemming, lemmatization, stop-word removal, etc. to clean the text data. However, in Transformer models, we don't need to do these preprocessing steps. The only thing we need to do is tokenization. Here is the steps we need to follow for text preprocessing in Transformer models:
- Tokenization
- Map tokens to integers (i.e. "Internal database system" -> [333, 12, 45])
- Padding / Truncating (to process batches of different length sequences)
Tokenization
Tokenization is the process of dividing text into smaller units called tokens, which can be words, phrases, subwords, or characters. In the context of Transformer models, tokenization is a crucial step in preprocessing text data for use in natural language processing tasks.
Tokenization helps the model to identify the underlying structure of the text and process it more efficiently. It enables the model to handle variations in language and handle words with multiple meanings or forms. The choice of tokenization method depends on the task and language being processed and can be a major factor in determining the effectiveness of the model.
Tokenization is an essential step in the text preprocessing pipeline for Transformer models and plays a crucial role in the overall performance of the model.
Types of Tokenization
Word-level Tokenization
Word-level tokenization is a method of dividing text into smaller units called tokens, where each token is a single word.
For example, consider the following sentence:
In word-level tokenization, the sentence would be tokenized as follows:
Each token is treated as a separate entity and can be processed individually. Word-level tokenization is simple and straightforward, but it can result in difficulties in handling words with multiple meanings or forms. It is also limited by the vocabulary size and cannot handle out-of-vocabulary words.
Character-level Tokenization
Character-level tokenization is a method of dividing text into smaller units called tokens, where each token is a single character.
For example, condider the following sentence:
In character-level tokenization, the sentence would be tokenized as follows:
Each token is treated as a separate entity and can be processed individually.
Character-level tokenization is useful for handling out-of-vocabulary words and can handle variations in language and words with multiple meanings or forms. However, it can result in longer sequences and may require more computational resources.
Subword-level Tokenization
Subword-level tokenization is a method of dividing text into smaller units called tokens, where each token is a subword unit, typically a sequence of characters. This method of tokenization is used when processing natural language text and aims to capture both the meaning of individual words and the relationships between subword units within words.
For example, consider the following sentence:
In subword-level tokenization, the sentence would be tokenized as follows:
In this example, subword-level tokenization has divided words like “quick” and “jump” into subword units, capturing both the meaning of individual words and the relationships between subword units within words.
Subword-level tokenization is a popular method of tokenization in NLP and is used in many state-of-the-art NLP models, including Transformer models. It provides a trade-off between the fine-grained representation of character-level tokenization and the simplicity of word-level tokenization, and can lead to improved performance in many NLP tasks.
Mapping Tokens to Integers
Mapping tokens to integers in transformers refers to the process of encoding text into numerical representations that can be processed by machine learning models. In NLP, tokens are usually words, subwords, or characters, and mapping them to integers involves assigning a unique integer value to each token. This integer representation is used to represent the text data in a numerical format that can be used by deep learning models, such as transformers.
The mapping is typically performed by creating a vocabulary of the tokens in the text corpus and assigning each token an integer value based on its frequency of occurrence in the corpus. The most common tokens are assigned lower integer values, while less frequent tokens are assigned higher values. This mapping process allows the model to process the text data efficiently and make predictions based on the underlying patterns in the data.
Here’s a simple example of mapping tokens to integers in transformers:
Suppose we have a text corpus consisting of the following sentences:
We can start by creating a vocabulary of all the unique tokens in the text corpus. The vocabulary for this example would be:
Next, we can assign integer values to each token in the vocabulary based on their frequency of occurrence. For example, the most frequent token, "database", might be assigned the integer value 1, while the least frequent token, "consistency", might be assigned the integer value 22, and so on. The final mapping would look like this:
Finally, we can use this mapping to encode the text data into numerical representations. For example, the first sentence "WAL in database systems stands for Write-Ahead Logging." would be encoded as:
This encoded representation of the text data can then be fed into a transformer model for processing and prediction.
Padding / Truncating
Padding and truncation are preprocessing techniques used in transformers to ensure that all input sequences have the same length.
Padding refers to the process of adding extra tokens (usually a special token such as [PAD]) to the end of short sequences so that they all have the same length. This is done so that the model can process all the sequences in a batch simultaneously. The padded tokens do not carry any semantic meaning and are just used to fill up the extra space in the shorter sequences.
Truncation, on the other hand, refers to the process of cutting off the end of longer sequences so that they are all the same length. This is done to ensure that the model is not overwhelmed by very long sequences and to reduce the computational overhead of processing large sequences.
In transformers, padding and truncation are usually performed before feeding the input sequences into the model, and the maximum length for the sequences is set based on the specific task and the available computational resources. The choice of the maximum length is a trade-off between keeping enough information from the original sequence and reducing computational overhead.
Here’s a simple example of padding and truncation in transformers:
Suppose we have a batch of sequences with varying lengths:
And let’s say that we want to set the maximum length for all the sequences to be 10 tokens.
For padding, we would add the special token [PAD] to the end of each sequence until it reaches the maximum length of 10 tokens. The padded sequences would look like this:
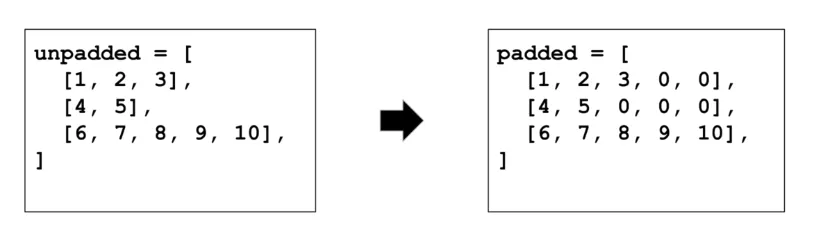
For truncation, we would cut off the end of each sequence so that it fits within the maximum length of 5 tokens. The truncated sequences would look like this:
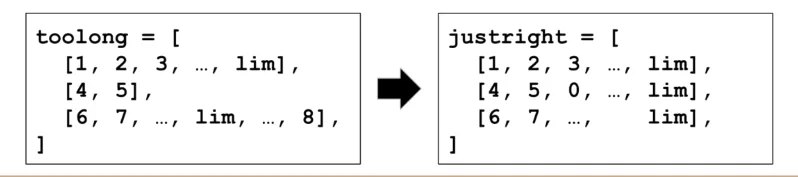
Note that the choice of padding or truncation, or a combination of both, will depend on the specific task and the desired trade-off between preserving information from the original sequence and reducing computational overhead.
Let's code
The command pip install transformers is used to install the transformers package, which provides access to state-of-the-art Transformer-based models for NLP tasks.
Once the transformers package is installed, you can import and use the Transformer-based models in your own projects.
Import AutoTokenizer class from transformers and build tokenizer object. There are different types of tokenizers but AutoTokenizer is a generic tokenizer that can handle various types of pre-trained models, including BERT, GPT-2, RoBERTa, XLNet, etc.
The code is using the AutoTokenizer class from the transformers library to load a pre-trained tokenizer for the BERT model with the base architecture and the cased version. The pre-trained tokenizer will be used to convert input sequences of text into numerical representations (tokens) that can be fed into the model. The checkpoint variable specifies the name of the pre-trained tokenizer to use, and the from_pretrained method is used to load the tokenizer from the transformers library's pre-trained models.
Print tokenizer details
Tokenizer object Tokenizer object
The BertTokenizerFast class is a tokenizer that is specifically designed for BERT-based models and provides tokenization functionalities for text data. The vocab_size attribute of the BertTokenizerFast instance is set to 28996, which means the vocabulary of the tokenizer consists of 28996 unique tokens.
The model_max_length attribute is set to 512, which indicates that the maximum length of the input sequence that the BERT model can handle is 512 tokens. This means that if the input sequence is longer than 512 tokens, it will be truncated to fit the maximum length.
The is_fast attribute is set to True, which means that the tokenization process is optimized for speed and is faster than other tokenization methods.
The padding_side attribute is set to "right", which means that the tokenizer will add padding tokens to the right side of the input sequence if it is shorter than the maximum length. The truncation_side attribute is set to "right", which means that the tokenizer will truncate the input sequence from the right side if it is longer than the maximum length.
The special_tokens attribute is a dictionary that contains the special tokens used in the BERT model, such as the unknown token ([UNK]), the separator token ([SEP]), the padding token ([PAD]), the class token ([CLS]), and the mask token ([MASK]). These special tokens play a crucial role in the BERT model's input and output encoding.
Test our tokenizer with a sample text
The code is applying the tokernizer object, which is an instance of the AutoTokenizer class, to the input text 'hello world'. The tokernizer object will convert the input text into a numerical representation that can be fed into the pre-trained model.
The output of the code is a dictionary with three keys:
-
input_ids: This is a list of integers that represent the numerical representation of the input text. Each integer corresponds to a token in the vocabulary of the pre-trained model. -
token_type_ids: This is a list of integers that indicate the type of each token in the input sequence. For example, in a sequence classification task, the first token of the input sequence could be marked as type 0, and the second token as type 1. -
attention_mask: This is a list of 1's and 0's that indicate which tokens should be attended to by the pre-trained model and which should be ignored. A 1 indicates that the token should be attended to, while a 0 indicates that the token should be ignored.
‘input_ids’: [101, 19082, 1362, 102] Note that there are 4 input ids because the input has been converted to: [CLS] hello world [SEP]
As we can see tokenizer’s output is a dictionary of lists, So we can not feed lists directly to the model. If we pass lists directly model will raise an error. It required tesnsor.
Proper model input
The return_tensors argument is set to 'pt', which indicates that the output should be in PyTorch tensor format.
The available options for return_tensors are:
'tf': Return TensorFlow tensors.'pt': Return PyTorch tensors.None: Return Python lists. This is the default value.
You can choose the appropriate option based on the deep learning framework you are using for your NLP model. If you are using PyTorch, you can set return_tensors to 'pt'. If you are using TensorFlow, you can set return_tensors to 'tf'. If you are not using a deep learning framework, you can use the default option, which returns Python lists.
Multiple inputs
As we can see, we have inputs of different lengths, so it is necessary to apply padding or truncation. If we haven’t applied padding and truncation model will not accept input of different lengths.
By setting padding to True, the tokenized inputs will be padded with a special padding token (usually represented by 0 in the vocabulary) so that all inputs have the same length. This is often necessary in NLP tasks, as many models expect a fixed-length input.
By setting truncation to True, if any of the input texts exceed the maximum length of the pre-trained model, they will be truncated to that maximum length. This is necessary to ensure that the inputs can be processed by the pre-trained model.
In Transformers, we only require the above text preprocessing steps, which is called Tokenization. After that, we can directly feed this preprocessed data to the model.