Introducing txtai, the all-in-one embeddings database
Tuesday, March 5, 2024
2554 words
13 min read
Last updated on Tuesday, March 5, 2024
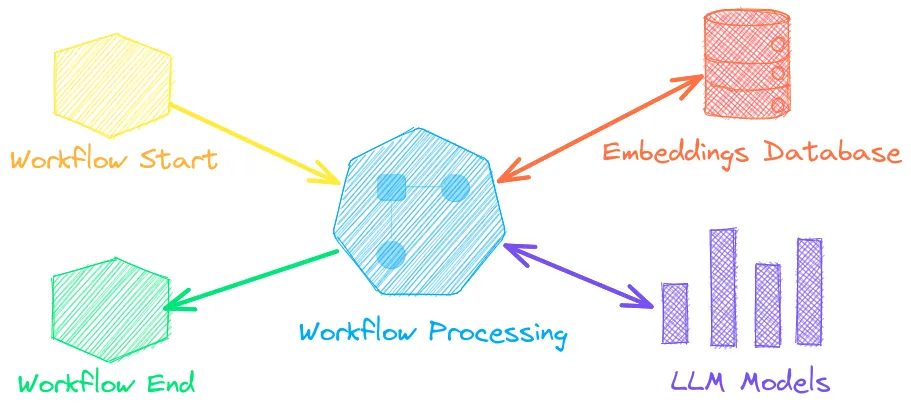
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
Search is the base of many applications. Once data starts to pile up, users want to be able to find it. It’s the foundation of the internet and an ever-growing challenge that is never solved or done.
The field of Natural Language Processing (NLP) is rapidly evolving with a number of new developments. Large-scale general language models are an exciting new capability allowing us to add amazing functionality. Innovation continues with new models and advancements coming in at what seems a weekly basis.
This article introduces txtai, an all-in-one embeddings database that enables Natural Language Understanding (NLU) based search in any application.
Introducing txtai
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
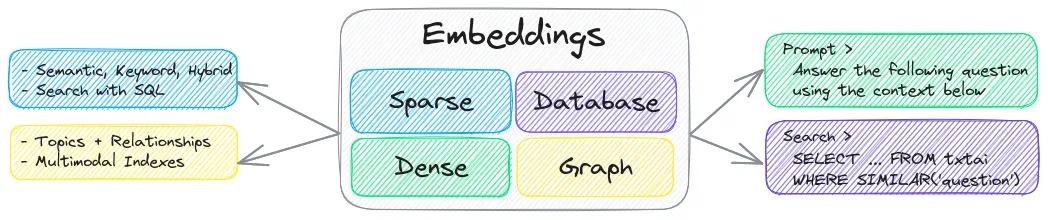
Embeddings databases are a union of vector indexes (sparse and dense), graph networks and relational databases. This enables vector search with SQL, topic modeling, retrieval augmented generation and more.
Embeddings databases can stand on their own and/or serve as a powerful knowledge source for large language model (LLM) prompts.
The following is a summary of key features:
🔎 Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
📄 Create embeddings for text, documents, audio, images and video
💡 Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarization and more
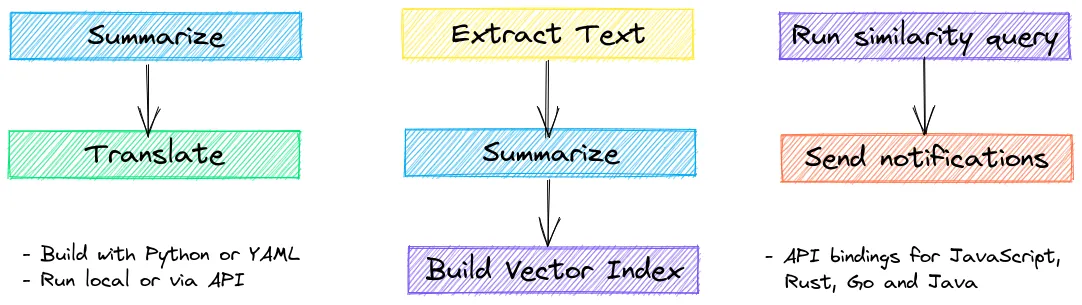
↪️️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
⚙️ Build with Python or YAML. API bindings available for JavaScript, Java, Rust and Go.
☁️ Run local or scale out with container orchestration
txtai can be installed via pip or Docker. The following shows how to install via pip.
bash
1pip install txtai
Semantic search
txtai enables semantic search with SQL and object storage.
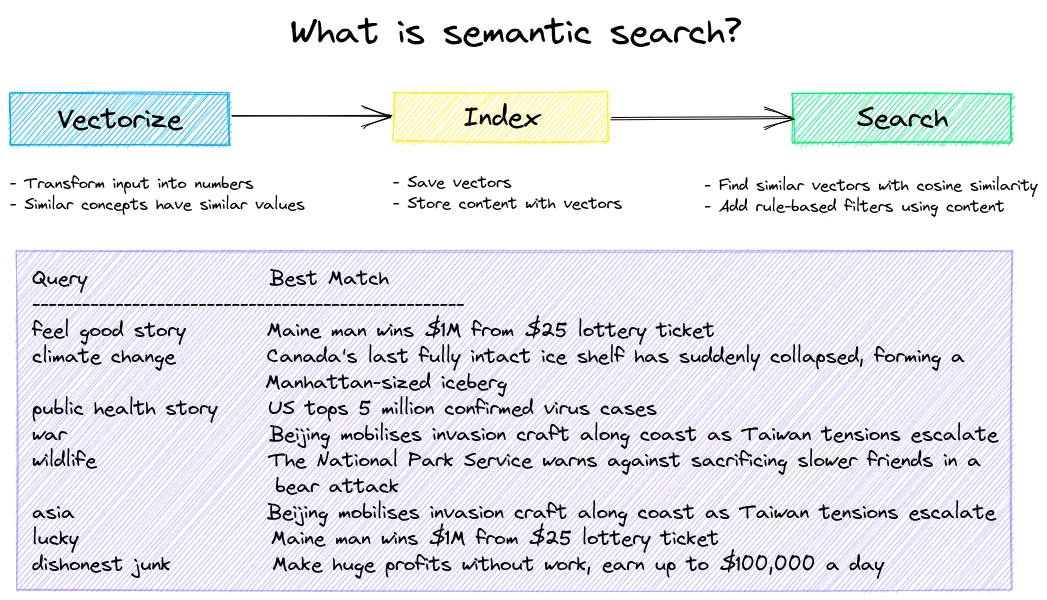
Embeddings databases are the engine that delivers semantic search. Data is transformed into embeddings vectors where similar concepts will produce similar vectors. Indexes both large and small are built with these vectors. The indexes are used to find results that have the same meaning, not necessarily the same keywords.
The basic use case for an embeddings database is building an approximate nearest neighbor (ANN) index for semantic search. The following example indexes a small number of text entries to demonstrate the value of semantic search.
python
1from txtai import Embeddings
23# Works with a list, dataset or generator4data =[5"US tops 5 million confirmed virus cases",6"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",7"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",8"The National Park Service warns against sacrificing slower friends in a bear attack",9"Maine man wins $1M from $25 lottery ticket",10"Make huge profits without work, earn up to $100,000 a day"11]1213# Create an embeddings14embeddings = Embeddings(path="sentence-transformers/nli-mpnet-base-v2")1516# Create an index for the list of text17embeddings.index(data)1819print("%-20s %s"%("Query","Best Match"))20print("-"*50)2122# Run an embeddings search for each query23for query in("feel good story","climate change",24"public health story","war","wildlife","asia",25"lucky","dishonest junk"):26# Extract uid of first result27# search result format: (uid, score)28 uid = embeddings.search(query,1)[0][0]2930# Print text31print("%-20s %s"%(query, data[uid]))
Results from semantic search example.
The example above shows that for all of the queries, the query text isn’t in the data. This is the true power of transformers models over token based search.
Updates and deletes
Updates and deletes are supported for embeddings. The upsert operation will insert new data and update existing data
The following section runs a query, then updates a value changing the top result and finally deletes the updated value to revert back to the original query results.
python
1# Run initial query2uid = embeddings.search("feel good story",1)[0][0]3print("Initial: ", data[uid])45# Create a copy of data to modify6udata = data.copy()78# Update data9udata[0]="See it: baby panda born"10embeddings.upsert([(0, udata[0],None)])1112uid = embeddings.search("feel good story",1)[0][0]13print("After update: ", udata[uid])1415# Remove record just added from index16embeddings.delete([0])1718# Ensure value matches previous value19uid = embeddings.search("feel good story",1)[0][0]20print("After delete: ", udata[uid])
shell
1Initial: Maine man wins $1M from $25 lottery ticket
2After update: See it: baby panda born
3After delete: Maine man wins $1M from $25 lottery ticket
1Canada's last fully intact ice shelf has suddenly collapsed, forming a
2Manhattan-sized iceberg
Hybrid search
While dense vector indexes are by far the best option for semantic search systems, sparse keyword indexes can still add value. There may be cases where finding an exact match is important.
Hybrid search combines the results from sparse and dense vector indexes for the best of both worlds.
python
1# Create an embeddings2embeddings = Embeddings(3 hybrid=True,4 path="sentence-transformers/nli-mpnet-base-v2"5)67# Create an index for the list of text8embeddings.index(data)910print("%-20s %s"%("Query","Best Match"))11print("-"*50)1213# Run an embeddings search for each query14for query in("feel good story","climate change",15"public health story","war","wildlife","asia",16"lucky","dishonest junk"):17# Extract uid of first result18# search result format: (uid, score)19 uid = embeddings.search(query,1)[0][0]2021# Print text22print("%-20s %s"%(query, data[uid]))
Results from hybrid search example.
Same results as with semantic search. Let’s run the same example with just a keyword index to view those results.
python
1# Create an embeddings2embeddings = Embeddings(keyword=True)34# Create an index for the list of text5embeddings.index(data)67print(embeddings.search("feel good story"))8print(embeddings.search("lottery"))
shell
1[]2[(4, 0.5234998733628726)]
See that when the embeddings instance only uses a keyword index, it can’t find semantic matches, only keyword matches.
Content storage
Up to this point, all the examples are referencing the original data array to retrieve the input text. This works fine for a demo but what if you have millions of documents? In this case, the text needs to be retrieved from an external datastore using the id.
Content storage adds an associated database (i.e. SQLite, DuckDB) that stores associated metadata with the vector index. The document text, additional metadata and additional objects can be stored and retrieved right alongside the indexed vectors.
python
1# Create embeddings with content enabled.2# The default behavior is to only store indexed vectors.3embeddings = Embeddings(4 path="sentence-transformers/nli-mpnet-base-v2",5 content=True,6 objects=True7)89# Create an index for the list of text10embeddings.index(data)1112print(embeddings.search("feel good story",1)[0]["text"])
shell
1Maine man wins $1M from $25 lottery ticket
The only change above is setting the content flag to True. This enables storing text and metadata content (if provided) alongside the index. Note how the text is pulled right from the query result!
Let’s add some metadata.
Query with SQL
When content is enabled, the entire dictionary is stored and can be queried. In addition to vector queries, txtai accepts SQL queries. This enables combined queries using both a vector index and content stored in a database backend.
python
1# Create an index for the list of text2embeddings.index([{"text": text,"length":len(text)}for text in data])34# Filter by score5print(embeddings.search("select text, score from txtai where similar('hiking danger') and score >= 0.15"))67# Filter by metadata field 'length'8print(embeddings.search("select text, length, score from txtai where similar('feel good story') and score >= 0.05 and length >= 40"))910# Run aggregate queries11print(embeddings.search("select count(*), min(length), max(length), sum(length) from txtai"))
shell
1[{'text':'The National Park Service warns against sacrificing slower friends in a bear attack', 'score':0.3151373863220215}]2[{'text':'Maine man wins $1M from $25 lottery ticket', 'length':42, 'score':0.08329027891159058}]3[{'count(*)':6, 'min(length)':39, 'max(length)':94, 'sum(length)':387}]
This example above adds a simple additional field, text length.
Note the second query is filtering on the metadata field length along with a similar query clause. This gives a great blend of vector search with traditional filtering to help identify the best results.
Object storage
In addition to metadata, binary content can also be associated with documents. The example below downloads an image, upserts it along with associated text into the embeddings index.
python
1import urllib
23from IPython.display import Image
45# Get an image6request = urllib.request.urlopen("https://raw.githubusercontent.com/neuml/txtai/master/demo.gif")78# Upsert new record having both text and an object9embeddings.upsert([("txtai",{"text":"txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.","object": request.read()},None)])1011# Query txtai for the most similar result to "machine learning" and get associated object12result = embeddings.search("select object from txtai where similar('machine learning') limit 1")[0]["object"]1314# Display image15Image(result.getvalue(), width=600)
Searching with txtai.
Topic modeling
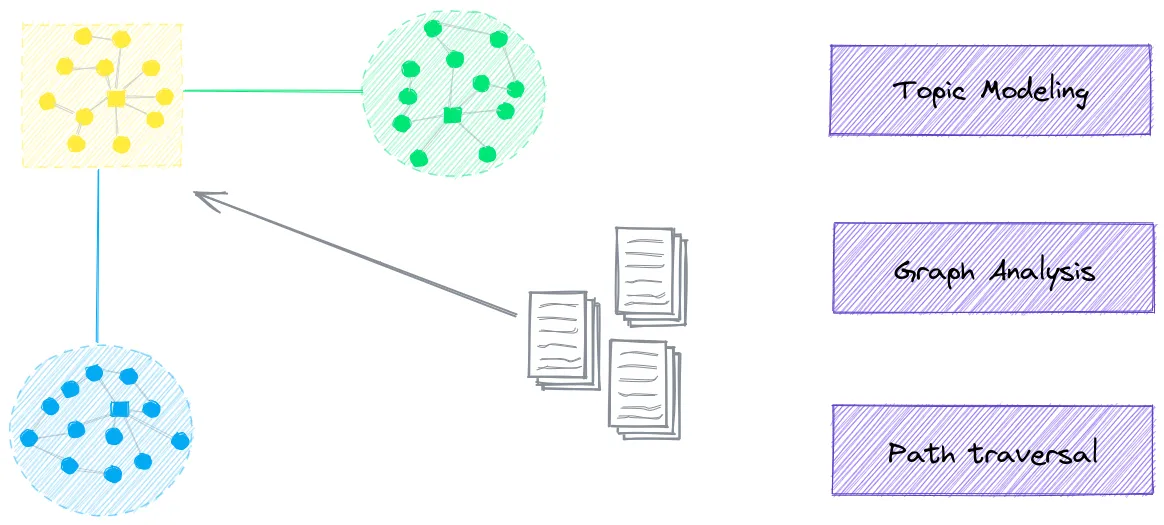
txtai enables topic modeling with semantic graphs.
Topic modeling is enabled via semantic graphs. Semantic graphs, also known as knowledge graphs or semantic networks, build a graph network with semantic relationships connecting the nodes. In txtai, they can take advantage of the relationships inherently learned within an embeddings index.
python
1# Create embeddings with a graph index2embeddings = Embeddings(3 path="sentence-transformers/nli-mpnet-base-v2",4 content=True,5 functions=[6{"name":"graph","function":"graph.attribute"},7],8 expressions=[9{"name":"category","expression":"graph(indexid, 'category')"},10{"name":"topic","expression":"graph(indexid, 'topic')"},11],12 graph={13"topics":{14"categories":["health","climate","finance","world politics"]15}16}17)1819embeddings.index(data)20embeddings.search("select topic, category, text from txtai")
shell
1[{'topic':'confirmed_cases_us_5',
2'category':'health',
3'text':'US tops 5 million confirmed virus cases'},
4{'topic':'collapsed_iceberg_ice_intact',
5'category':'climate',
6'text':"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg"},
7{'topic':'beijing_along_craft_tensions',
8'category':'world politics',
9'text':'Beijing mobilises invasion craft along coast as Taiwan tensions escalate'}]
When a graph index is enabled, topics are assigned to each of the entries in the embeddings instance. Topics are dynamically created using a sparse index over graph nodes grouped by community detection algorithms.
Topic categories are also be derived as shown above.
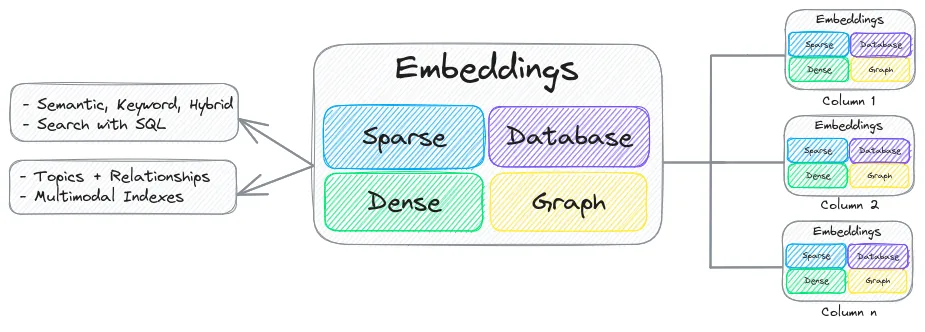
Subindexes
Subindexes can be configured for an embeddings. A single embeddings instance can have multiple subindexes each with different configurations.
We’ll build an embeddings index having both a keyword and dense index to demonstrate.
python
1# Create embeddings with subindexes2embeddings = Embeddings(3 content=True,4 defaults=False,5 indexes={6"keyword":{7"keyword":True8},9"dense":{10"path":"sentence-transformers/nli-mpnet-base-v2"11}12}13)14embeddings.index(data)
python
1embeddings.search("feel good story", limit=1, index="keyword")
shell
1[]
python
1embeddings.search("feel good story", limit=1, index="dense")
shell
1[{'id':'4',
2'text':'Maine man wins $1M from $25 lottery ticket',
3'score':0.08329027891159058}]
Once again, this example demonstrates the difference between keyword and semantic search. The first search call uses the defined keyword index, the second uses the dense vector index.
LLM orchestration
txtai enables LLM orchestration with a pipeline that extracts knowledge from content by joining a prompt, context data store and generative model together.
txtai is an all-in-one embeddings database. It is the only vector database that also supports sparse indexes, graph networks and relational databases with inline SQL support. In addition to this, txtai has support for LLM orchestration.
The extractor pipeline is txtai’s spin on retrieval augmented generation (RAG). This pipeline extracts knowledge from content by joining a prompt, context data store and generative model together.
The following example shows how a large language model (LLM) can use an embeddings database for context.
python
1import torch
2from txtai.pipeline import Extractor
34defprompt(question):5return[{6"query": question,7"question":f"""
8Answer the following question using the context below.
9Question: {question}10Context:
11"""12}]1314# Create embeddings15embeddings = Embeddings(16 path="sentence-transformers/nli-mpnet-base-v2",17 content=True,18 autoid="uuid5"19)2021# Create an index for the list of text22embeddings.index(data)2324# Create and run extractor instance25extractor = Extractor(26 embeddings,27"google/flan-t5-large",28 torch_dtype=torch.bfloat16,29 output="reference"30)31extractor(prompt("What country is having issues with climate change?"))[0]
The logic above first builds an embeddings index. It then loads a LLM and uses the embeddings index to drive a LLM prompt.
The extractor pipeline can optionally return a reference to the id of the best matching record with the answer. That id can be used to resolve the full answer reference. Note that the embeddings above used an uuid autosequence.
python
1uid = extractor(prompt("What country is having issues with climate change?"))[0]["reference"]2embeddings.search(f"select id, text from txtai where id = '{uid}'")
shell
1[{'id':'da633124-33ff-58d6-8ecb-14f7a44c042a',
2'text':"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg"}]
LLM inference can also be run standalone.
python
1from txtai.pipeline import LLM
23llm = LLM("google/flan-t5-large", torch_dtype=torch.bfloat16)4llm("Where is one place you'd go in Washington, DC?")
shell
1national museum of american history
Language model workflows
txtai enables language model workflows.
Language model workflows, also known as semantic workflows, connect language models together to build intelligent applications.
Workflows can run right alongside an embeddings instance, similar to a stored procedure in a relational database. Workflows can be written in either Python or YAML. We’ll demonstrate how to write a workflow with YAML.
The workflow above loads an embeddings index and defines a search workflow. The search workflow runs a search and then passes the results to a translation pipeline. The translation pipeline translates results to French.
python
1from txtai import Application
23# Build index4app = Application("embeddings.yml")5app.add(data)6app.index()78# Run workflow9list(app.workflow(10"search",11["select text from txtai where similar('feel good story') limit 1"]12))
shell
1['Maine homme gagne $1M à partir de $25 billet de loterie']
SQL functions, in some cases, can accomplish the same thing as a workflow. The function below runs the translation pipeline as a function.
python
1app.search("select translation(text, 'fr') text from txtai where similar('feel good story') limit 1")
shell
1[{'text':'Maine homme gagne $1M à partir de $25 billet de loterie'}]
LLM chains with templates are also possible with workflows. Workflows are self-contained, they operate both with and without an associated embeddings instance. The following workflow uses a LLM to conditionally translate text to French and then detect the language of the text.
yaml
1sequences:2path: google/flan-t5-large
3torch_dtype: torch.bfloat16
45workflow:6chain:7tasks:8-task: template
9template: Translate '{statement}' to {language} if it's English
10action: sequences
11-task: template
12template: What language is the following text?{text}13action: sequences
python
1inputs =[2{"statement":"Hello, how are you","language":"French"},3{"statement":"Hallo, wie geht's dir","language":"French"}4]56app = Application("workflow.yml")7list(app.workflow("chain", inputs))
shell
1['French', 'German']
Wrapping up
NLP is advancing at a rapid pace. Things not possible even a year ago are now possible. This article introduced txtai, an all-in-one embeddings database. The possibilities are limitless and we’re excited to see what can be built on top of txtai!