

For the vast majority of LLM use cases, we can build practical LLM-powered applications by integrating prompt engineer. However, there are situations where prompting an existing LLM out-of-the-box doesn’t cut it, and a more sophisticated solution is required. This is where model fine-tuning can help.
What is Fine-tuning?
Fine-tuning is taking a pre-trained model and training at least one internal model parameter (i.e. weights). In the context of LLMs, what this typically accomplishes is transforming a general-purpose base model (e.g. GPT-3) into a specialized model for a particular use case (e.g. ChatGPT) [1].
The key upside of this approach is that models can achieve better performance while requiring (far) fewer manually labeled examples compared to models that solely rely on supervised training.
While strictly self-supervised base models can exhibit impressive performance on a wide variety of tasks with the help of prompt engineering [2], they are still word predictors and may generate completions that are not entirely helpful or accurate. For example, let’s compare the completions of davinci (base GPT-3 model) and text-davinci-003 (a fine-tuned model).

Notice the base model is simply trying to complete the text by listing a set of questions like a Google search or homework assignment, while the fine-tuned model gives a more helpful response. The flavor of fine-tuning used for text-davinci-003 is alignment tuning, which aims to make the rLLM’s responses more helpful, honest, and harmless, but more on that later [3,4].
Why Fine-tune?
Fine-tuning not only improves the performance of a base model, but a smaller (fine-tuned) model can often outperform larger (more expensive) models on the set of tasks on which it was trained [4]. This was demonstrated by OpenAI with their first generation “InstructGPT” models, where the 1.3B parameter InstructGPT model completions were preferred over the 175B parameter GPT-3 base model despite being 100x smaller [4].
Although most of the LLMs we may interact with these days are not strictly self-supervised models like GPT-3, there are still drawbacks to prompting an existing fine-tuned model for a specific use case.
A big one is LLMs have a finite context window. Thus, the model may perform sub-optimally on tasks that require a large knowledge base or domain-specific information [1]. Fine-tuned models can avoid this issue by “learning” this information during the fine-tuning process. This also precludes the need to jam-pack prompts with additional context and thus can result in lower inference costs.
3 Ways to Fine-tune
There are 3 generic ways one can fine-tune a model: self-supervised, supervised, and reinforcement learning. These are not mutually exclusive in that any combination of these three approaches can be used in succession to fine-tune a single model.
Self-Supervised Learning
Self-supervised learning consists of training a model based on the inherent structure of the training data. In the context of LLMs, what this typically looks like is given a sequence of words (or tokens, to be more precise), predict the next word (token).
While this is how many pre-trained language models are developed these days, it can also be used for model fine-tuning. A potential use case of this is developing a model that can mimic a person’s writing style given a set of example texts.
Supervised Learning
The next, and perhaps most popular, way to fine-tune a model is via supervised learning. This involves training a model on input-output pairs for a particular task. An example is instruction tuning, which aims to improve model performance in answering questions or responding to user prompts [1,3].
The key step in supervised learning is curating a training dataset. A simple way to do this is to create question-answer pairs and integrate them into a prompt template [1,3]. For example, the question-answer pair: Who was the 35th President of the United States? — John F. Kennedy could be pasted into the below prompt template. More example prompt templates are available in section A.2.1 of ref [4].
Using a prompt template is important because base models like GPT-3 are essentially “document completers”. Meaning, given some text, the model generates more text that (statistically) makes sense in that context.
Reinforcement Learning
Finally, one can use reinforcement learning (RL) to fine-tune models. RL uses a reward model to guide the training of the base model. This can take many different forms, but the basic idea is to train the reward model to score language model completions such that they reflect the preferences of human labelers [3,4]. The reward model can then be combined with a reinforcement learning algorithm (e.g. Proximal Policy Optimization (PPO)) to fine-tune the pre-trained model.
An example of how RL can be used for model fine-tuning is demonstrated by OpenAI’s InstructGPT models, which were developed through 3 key steps [4].
-
Generate high-quality prompt-response pairs and fine-tune a pre-trained model using supervised learning. (~13k training prompts) Note: One can (alternatively) skip to step 2 with the pre-trained model [3].
-
Use the fine-tuned model to generate completions and have human-labelers rank responses based on their preferences. Use these preferences to train the reward model. (~33k training prompts).
-
Use the reward model and an RL algorithm (e.g. PPO) to fine-tune the model further. (~31k training prompts).
While the strategy above does generally result in LLM completions that are significantly more preferable to the base model, it can also come at a cost of lower performance in a subset of tasks. This drop in performance is also known as an alignment tax [3,4].
Supervised Fine-tuning Steps (High-level)
As we saw above, there are many ways in which one can fine-tune an existing language model. However, for the remainder of this article, we will focus on fine-tuning via supervised learning. Below is a high-level procedure for supervised model fine-tuning [1].
-
Choose fine-tuning task (e.g. summarization, question answering, text classification)
-
Prepare training dataset i.e. create (100–10k) input-output pairs and preprocess data (i.e. tokenize, truncate, and pad text).
-
Choose a base model (experiment with different models and choose one that performs best on the desired task).
-
Fine-tune model via supervised learning
-
Evaluate model performance (i.e. calculate accuracy, precision, recall, F1 score, etc.)
Let's focus on step 4 in this article.
3 Options for Parameter Training
When it comes to fine-tuning a model with ~100M-100B parameters, one needs to be thoughtful of computational costs. Toward this end, an important question is — which parameters do we (re)train?
With the mountain of parameters at play, we have countless choices for which ones we train. Here, I will focus on three generic options of which to choose.
Option 1: Retrain all parameters
The first option is to train all internal model parameters (called full parameter tuning) [3]. While this option is simple (conceptually), it is the most computationally expensive. Additionally, a known issue with full parameter tuning is the phenomenon of catastrophic forgetting. This is where the model “forgets” useful information it “learned” in its initial training [3].
One way we can mitigate the downsides of Option 1 is to freeze a large portion of the model parameters, which brings us to Option 2.
Option 2: Transfer Learning
The big idea with transfer learning (TL) is to preserve the useful representations/features the model has learned from past training when applying the model to a new task. This generally consists of dropping “the head” of a neural network (NN) and replacing it with a new one (e.g. adding new layers with randomized weights). Note: The head of an NN includes its final layers, which translate the model’s internal representations to output values.
While leaving the majority of parameters untouched mitigates the huge computational cost of training an LLM, TL may not necessarily resolve the problem of catastrophic forgetting. To better handle both of these issues, we can turn to a different set of approaches.
Option 3: Parameter Efficient Fine-tuning (PEFT)
PEFT involves augmenting a base model with a relatively small number of trainable parameters. The key result of this is a fine-tuning methodology that demonstrates comparable performance to full parameter tuning at a tiny fraction of the computational and storage cost [5].
PEFT encapsulates a family of techniques, one of which is the popular LoRA (Low-Rank Adaptation) method [6]. The basic idea behind LoRA is to pick a subset of layers in an existing model and modify their weights according to the following equation.
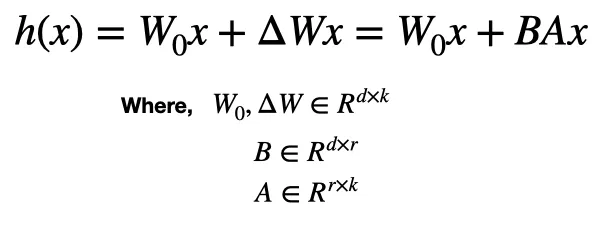
Where h() = a hidden layer that will be tuned, x = the input to h(), W₀ = the original weight matrix for the h, and ΔW = a matrix of trainable parameters injected into h. ΔW is decomposed according to ΔW=BA, where ΔW is a d by k matrix, B is d by r, and A is r by k. r is the assumed “intrinsic rank” of ΔW (which can be as small as 1 or 2) [6].
The key point is the (d * k) weights in W₀ are frozen and, thus, not included in optimization. Instead, the ((d r) + (r k)) weights making up matrices B and A are the only ones that are trained.
Plugging in some made-up numbers for d=100, k=100, and r=2 to get a sense of the efficiency gains, the number of trainable parameters drops from 10,000 to 400 in that layer. In practice, the authors of the LoRA paper cited a 10,000x reduction in parameter checkpoint size using LoRA fine-tune GPT-3 compared to full parameter tuning [6].
To make this more concrete, let’s see how we can use LoRA to fine-tune a language model efficiently enough to run on a personal computer.
Example Code: Fine-tuning an LLM using LoRA
In this example, we will use the Hugging Face ecosystem to fine-tune a language model to classify text as ‘positive’ or ‘negative’. Here, we fine-tune distilbert-base-uncased, a ~70M parameter model based on BERT. Since this base model was trained to do language modeling and not classification, we employ transfer learning to replace the base model head with a classification head. Additionally, we use LoRA to fine-tune the model efficiently.
Imports
We start by importing helpful libraries and modules. Datasets, transformers, peft, and evaluate are all libraries from Hugging Face (HF).
Base model
Next, we load in our base model. The base model here is a relatively small one, but there are several other (larger) ones that we could have used (e.g. roberta-base, llama2, gpt2). A full list is available here.
Load data
We can then load our training and validation data from HF’s datasets library. This is a dataset of 2000 movie reviews (1000 for training and 1000 for validation) with binary labels indicating whether the review is positive (or not).
Preprocess data
Next, we need to preprocess our data so that it can be used for training. This consists of using a tokenizer to convert the text into an integer representation understood by the base model.
To apply the tokenizer to the dataset, we use the .map() method. This takes in a custom function that specifies how the text should be preprocessed. In this case, that function is called tokenize_function(). In addition to translating text to integers, this function truncates integer sequences such that they are no longer than 512 numbers to conform to the base model’s max input length.
At this point, we can also create a data collator, which will dynamically pad examples in each batch during training such that they all have the same length. This is computationally more efficient than padding all examples to be equal in length across the entire dataset.
Evaluate metrics
We can define how we want to evaluate our fine-tuned model via a custom function. Here, we define the compute_metrics() function to compute the model’s accuracy.
Untrained model performance
Before training our model, we can evaluate how the base model with a randomly initialized classification head performs on some example inputs.
As expected, the model performance is equivalent to random guessing. Let’s see how we can improve this with fine-tuning.
Fine-tuning with LoRA
To use LoRA for fine-tuning, we first need a config file. This sets all the parameters for the LoRA algorithm. See comments in the code block for more details.
We can then create a new version of our model that can be trained via PEFT. Notice that the scale of trainable parameters was reduced by about 100x.
Next, we define hyperparameters for model training.
Finally, we create a trainer() object and fine-tune the model!
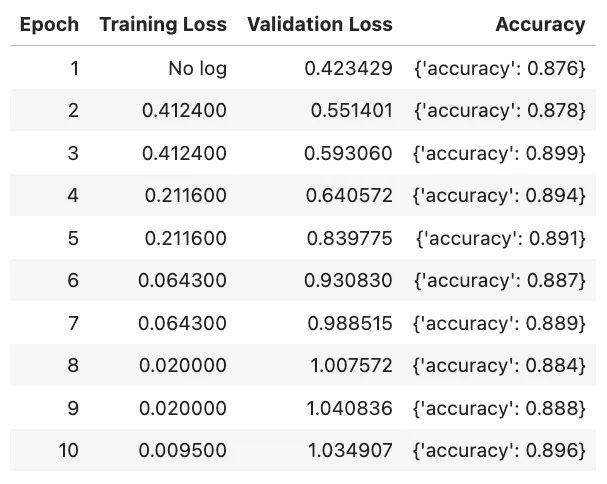
The above code will generate the following table of metrics during training.
Trained model performance
To see how the model performance has improved, let’s apply it to the same 5 examples from before.
The fine-tuned model improved significantly from its prior random guessing, correctly classifying all but one of the examples in the above code. This aligns with the ~90% accuracy metric we saw during training.
Conclusion
While fine-tuning an existing model requires more computational resources and technical expertise than using one out-of-the-box, (smaller) fine-tuned models can outperform (larger) pre-trained base models for a particular use case, even when employing clever prompt engineering strategies. Furthermore, with all the open-source LLM resources available, it’s never been easier to fine-tune a model for a custom application.