

High-level design
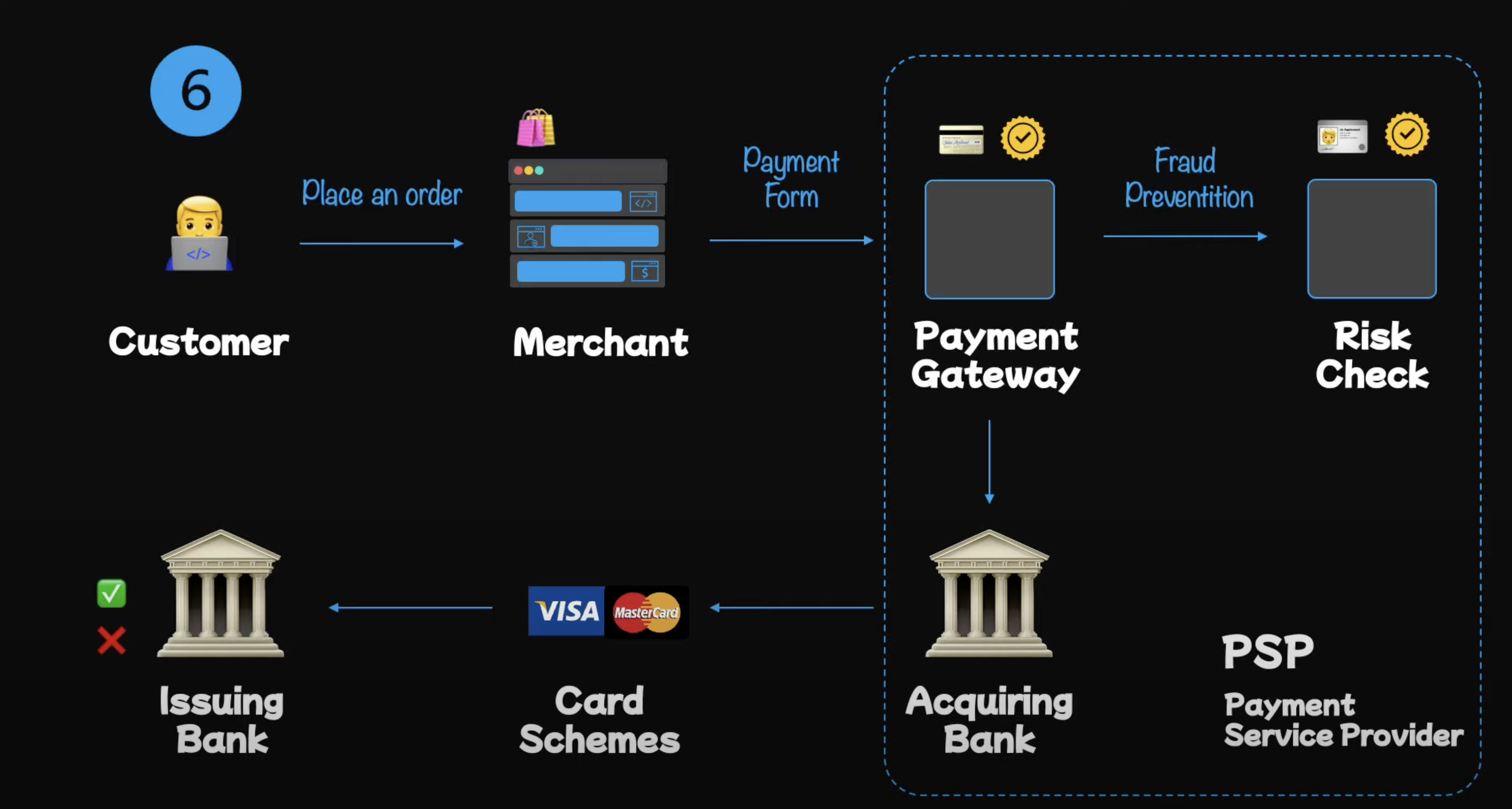
The high-level design of a payment system is quite simple. It consists of the following components:
-
Client: The client is the entity that initiates the payment request. It could be a web application, mobile application, or any other system that needs to charge the user.
-
Payment Gateway: The payment gateway is the system that processes the payment request. It is responsible for validating the payment request, charging the user, and sending the payment confirmation to the client. (PCI DSS compliance is required for payment gateways.)
-
Risk Check System: The risk check system is responsible for checking the risk associated with the payment request. It checks for fraud, credit card blacklists, and other risk factors. The Payment Gateway sends the payment request to the Risk Check System before processing the payment.
-
Acquiring Bank: The acquiring bank is the bank that processes the payment. The main function of the Payment Gateway is to validate financial credentials and transfer them to Acquiring Bank. This is the bank that processes card payments on behalf of the merchant.
-
PSP (Payment Service Provider): The PSP is a third-party service that provides the merchant with the ability to accept payments. It is responsible for the technical infrastructure and security of the payment system. PSP usually offers services such as fraud protection, tokenization, and PCI DSS compliance. PSPs can also be the acquiring bank but not necessarily.
-
Issuer Bank: The issuer bank is the bank that issued the credit card to the user. It is responsible for authorizing the payment request and transferring the money from the user's account to the merchant's account. The Acquiring Bank captures the transaction information, performs basic validation and routes the requests along the the appropriate card networks the the cardholder's Issuer Bank for approval. The Issuer Bank checks the user's account for sufficient funds and standing, and then sends a response back to the Acquiring Bank.
After that processes, the transaction follows the same route back to the Payment Gateway and then to the Client.
Establish the Goals
Before we start designing the system, we need to establish the requirements of the system and define what we want to achieve. We need to clarify the functional needs, the scope of the system, and the non-functional requirements.
What payment system are we building?
There are basically two ways to build a payment system:
-
Using a PSP (Common): We can use Stripe or PayPal to handle the payment processing. This is the easiest way to build a payment system. We can use the PSP's API to charge the user and handle the payment processing. The PSP will handle the risk check, acquiring bank, and issuer bank. We only need to integrate the PSP's API into our system. PSP moves money from the buyer account to the merchant account and takes a fee for the service.
-
Direct connection to a card schemes (Uncommon): We can build the payment system from scratch. This is the most complex way to build a payment system. We need to handle the risk check, acquiring bank, and issuer bank ourselves. We need to be PCI DSS compliant and handle the security of the payment system ourselves. Moreover, for every country, the process is different.
Using a PSP (Payment Service Provider)
When using PSP, we don't need to store the user's credit card information. This will give us many benefits:
- Strict ingress and egress networking control
- Strong infrastructure isolation
- Data integrity and security
- Secure cardholder data handling
A payment system interacts with a lot of internal services and external services. When one of the services fails, we may see unconsistent states. Therefore, we need to plan for transaction failures and perform reconciliation to fix any inconsistencies. This leads us the the system requirements.
Functional and Non-functional requirements
A payment system is easy to understand at the functional level. It needs to be able to move money from the buyer's account to the merchant's account. However, what's more difficult is to make the system reliable especially when unknown situations are revealed a small slip could potentially cause significant revenue loss. In this article, we will focus more in the technical concepts as they are applicable to almost every payment system. The business part will depend on the specific requirements of the system.
Payment system components
- Payment service: Display payment status and store order details.
- PSP integration: Secure payments.
- Wallet: Balance View.
- Ledger: Accounting, Analytics, and Reporting.
Below is the flow of a payment system:
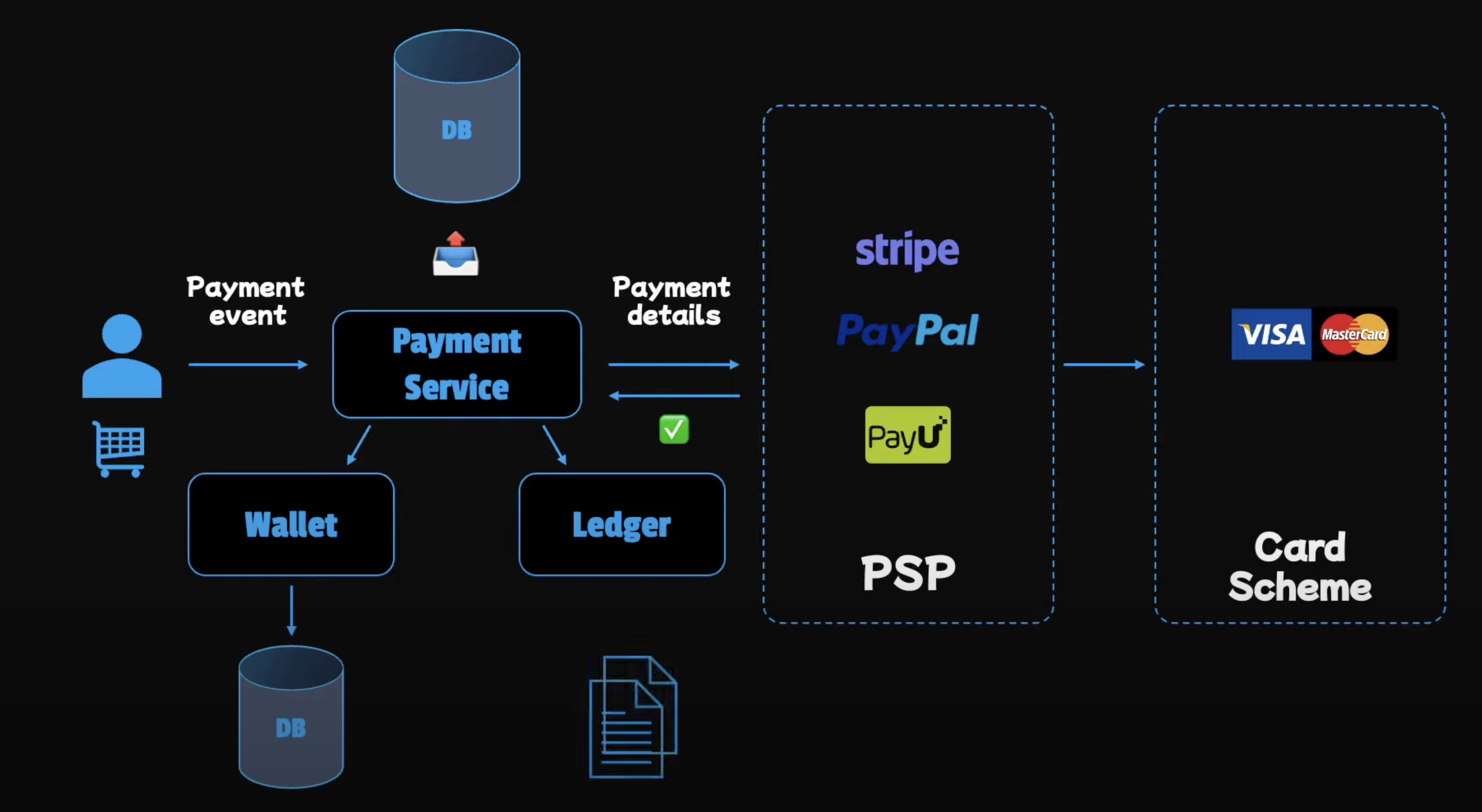
First, user clicks on the "Pay" button. This will trigger the Payment event. The payment service will then send the payment request to the PSP. The PSP is to send card details to Banks or Card schemes. After the PSP successfully processes the payment, it will send the payment status to the payment service. The payment service will have to do 2 main tasks:
- Update balance information of the wallet in the database.
- Update the ledger: Involving logging all the financial transactions record for later review and updating the information in the database.
Asynchronous communication
-
Reliable and faut-tolerant: Internal and external services need to talk to each other. We need to make sure that the system is reliable and fault-tolerant. Differ from synchronous communication, asynchronous communication doesn't wait for the response. It sends the message and continues to do other things (interval of time or be notified by the receiver). This is a good way to make the system more reliable and fault-tolerant.
-
Avoid Tight Coupling: Any of the services can fail at any time maybe because of network issues, hardware issues, or software issues. Synchronous communication is not tolerant to failures and big latencies. As a result, it will reduce the availability of the system. Therefore, we need to use asynchronous communication to make the system more reliable and fault-tolerant. However, in some cases, we need to use synchronous communication. For example, when the user is in physical store and the payment needs to be processed immediately.
-
Easier to deal with Uneven Traffic and Spikes: Asynchronous communication is also good for dealing with uneven traffic and spikes. For example, when the user is buying a ticket for a concert, there will be a spike in traffic. For this case, we can use message queues to handle the traffic. The message queue will store the messages and process them one by one. This will make the system more reliable and fault-tolerant.

We even have enough time to spin up more instances of the service to handle the traffic. In website, Kafka states that it is used by 7 out of 10 largest banks in the world.
As a result, asynchronous communication is a good solution for online shopping, fault detection and analytics.
System Failures
- System Failure: The system can fail at any time. Maybe because of network issues, hardware issues, or software issues.
- Poison Pill Errors: When an inbound message can not be processed or consumed.
- Functional Bugs: There is no technical errors but the results are invalid.
Fortunately, we have many tools to handle these issues. For example, we can use dead-letter queues to handle poison pill errors. We can use monitoring to detect system failures. We can use reconciliation to fix any inconsistencies. We can use circuit breakers to handle functional bugs.
Guarantee Transaction Completeness
To guarantee transaction completion, we can use a message queue lake Apache Kafka. For any order replaces or paid, we can create an event in Kafka. This will help us persist communication messages so that they are not lost even when things don't go as planned.
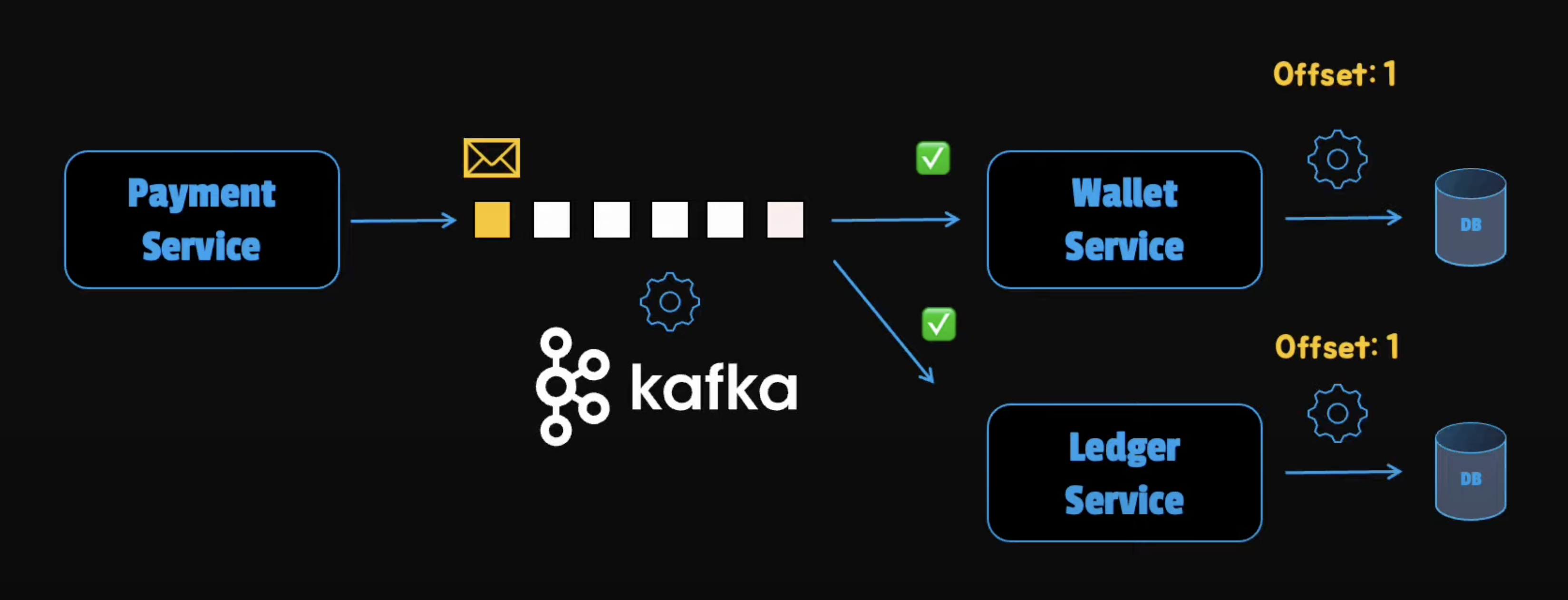
In this case, the payment operation doesn't complete successfully until the event is safely stored in the message queue. Because the Kafka's availability is 99.99%, we can guarantee that it can store the event safely. Then, these messages can be consumed by the other services to update the balance information of the wallet and update the ledger. Once the message is consumed, the transaction is complete.
Dealing with Transient Failures
Sometimes, in order to complete a transaction, we need to receive a response from the other services. For instance, we need to handle a get query. In this case, we can not use message queues.
Retrying
Time interval is important. If we retry too soon, we may overload the service. If we retry too late, we may lose the user. We can use exponential backoff in which the time interval increases exponentially to avoid overloading the service.
When multiple services are dependent on one service, we can use apply some randomness to the client's wait time. This will help us avoid the thundering herd problem.
Timeout pattern
Timeout is created to solve the problem of waiting for a response from the other services. The incorrect timeout can lead to double charging or lost revenue. We need to set the timeout to be long enough to handle the traffic but short enough to avoid double charging.
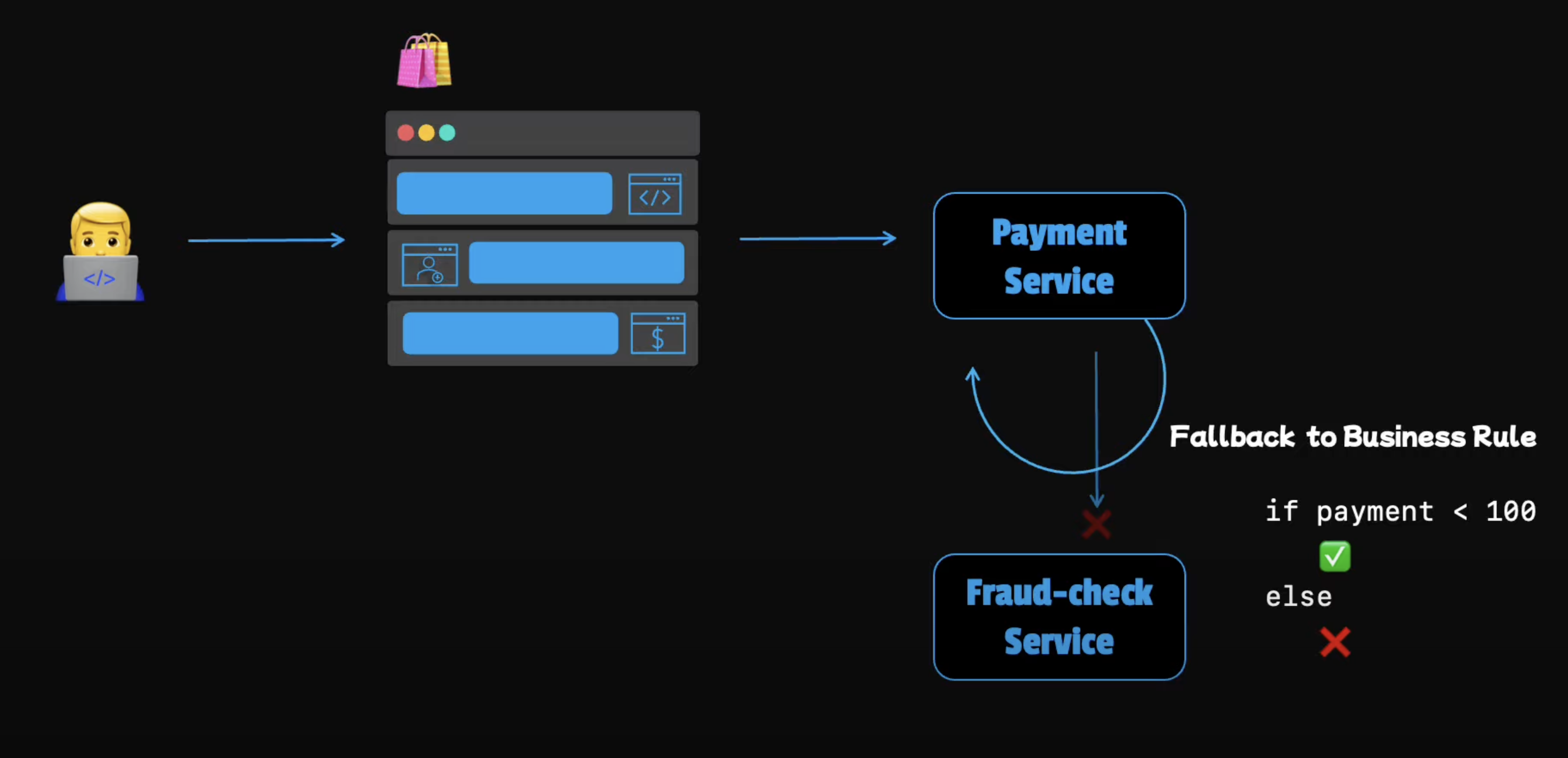
Fall back pattern
While making a payment, a request might be sent to the fraud check service but let's say that this service returns an "Internal Server Error" instead of aborting the whole computation. Because of a missing response we can use a fallback to handle the situation. Otherwise we can lose the user if the payment fails.
For example, we can fall back to a simple business role, if the amount is reasonably small, we can simply let the transactions go through. This is compromise between risk and keeping the customers happy. Next, we will see what we can do if the fallback value is not acceptable.
Dealing with Persistent Failures
Some failures can persist for a couple of minutes or even hours. In those cases, what can we do?
-
Cancel the Request: If the failure is acceptable business-wise, we can simply cancel the request.
-
Consider Compatibility Issues: Sometimes, failures persist because the information is not compatible between the sender and the receiver. These errors may not be retrievable because, no matter how many times we resend the information, it will always fail. Such incompatible messages are also called poison pill errors. To isolate the problematic messages, we can save them for later debugging. For instance, we can save them in a dedicated queue so that we get rid of the broken messages. This pattern is also known as the dead letter queue. Later, these messages can be inspected to determine why they are not processed successfully.
-
Handle Service Outages: In other cases, an error may persist because one of the services is down, maybe for a couple of hours due to a serious problem. In that case, the error is retrievable, so we may still want to accept the request because we know we can process them later when the failed service recovers. Basically, we store all the transactions that have failed and need to be consumed later in a persistent queue. When the crashed service is up again, we can pick the transactions from the queue and process them.
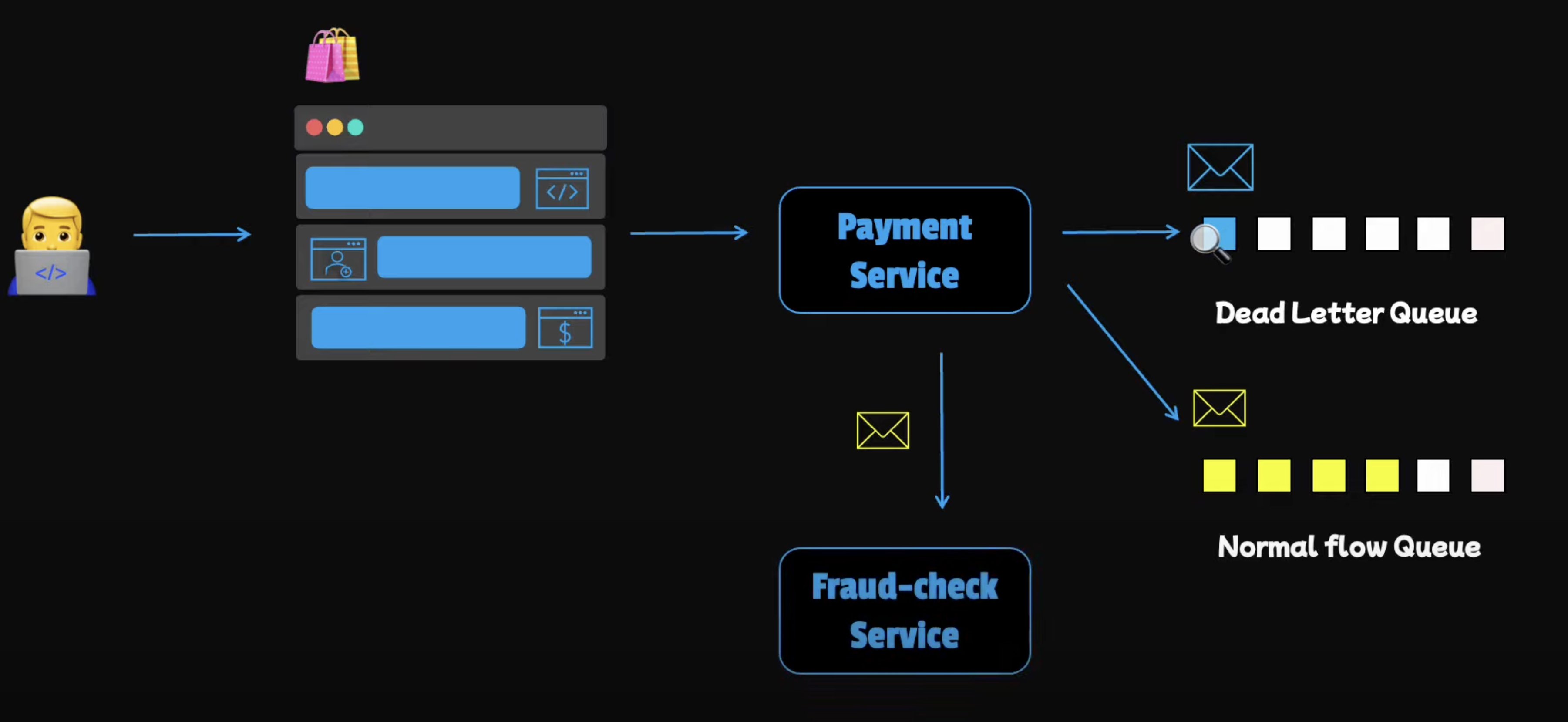
Idempotency (Avoiding Double Charging)
If a payment request fails due to a network error or any other reason, we should have a mechanism to safely retry the operation without charging the customer twice. To achieve this, we'll use the concept of idempotency.
From an API perspective, an idempotent operation is one that has no additional effect if it's called more than once with the same input parameters. Let's see a usual scenario to understand how it actually works:
- A customer makes a payment.
- The payment goes through our payment system and is successfully processed by the PSP (Payment Service Provider).
- However, due to network errors, the response of the transaction fails to reach back to our payment system.
- The user will get back an error and may try to click the pay button or retry the payment.
How can we avoid double payments at this point? We'll make use of an idempotent key. This is usually a unique value that is generated on the client side and expires after a certain period of time.
To perform an idempotent payment request, an idempotent key is added to the HTTP header. Here's how it typically looks (UUIDs are commonly used as idempotency keys):
Then, when the receiving server gets the same payment details it will identify that is a retry operation.
To support hidden potency we can use the unique key constraint of any database. When the payment system receives a payment it tries to insert a row into the database table. A successful insertion means we have not seen this payment request before. If the request fails it means the key is a duplicate so the second request is ignored. We can also return the latest status of the payment to the user.

If multiple concurrent requests are detected with the same hidden potency key, only one request is processed and the others will receive 429 Too Many Requests status code. In conclusion, an hidden potency key is a good way to avoid double charging.
Distributed Systems
Lastly, if our payment system stores and serves a lot of data but is limited by a single machine, we need to graduate to a distributed system. Here, we can spin up more database instances and also more payment services. Then, we can make use of the following benefits that it provides:
-
Redundancy: This is achieved using replication. Usually, a distributed system can have multiple copies of data and processes. This will help us improve reliability by providing a backup in case one component fails.
-
Workload Distribution: In distributive systems, we can distribute the workload across multiple machines, which can improve reliability because we reduce the risk of a single component being overwhelmed.
-
Fault Tolerance: Distributed systems can be designed to be tolerant of failures, allowing them to continue functioning even if one or more components fail.
-
Scalability: We can easily scale up or down by adding or removing components, which again helps us improve reliability by allowing the system to handle increased or decreased workloads.
However, we should be aware that in a distributed system, the communication between any two nodes can fail, causing data inconsistency. Replication lag could cause inconsistent data between the primary database and the replicas. So, we should be aware of what consistency level we use when we read or write some data.
The Pillars of Encryption and Robust Security Measures
In the digital age, where data is king, safeguarding sensitive information has become paramount. One of the most formidable weapons in our arsenal against data breaches is encryption. Let's delve into the intricacies of encryption and explore the robust security measures necessary to fortify our data defenses.
Encryption: A Shield for Data Protection
Encryption serves as a formidable shield, rendering data unreadable to unauthorized parties. It operates on two fronts: at rest and in transit.
Encrypting Data at Rest
Encrypting data at rest involves converting it into a secure format that remains indecipherable without the appropriate decryption key. Utilizing sophisticated software tools, such as disk encryption and database encryption, ensures that sensitive information remains impervious to prying eyes, even when stored on local machines or servers.
Secure Transmission with Encryption
Data transmission over networks, particularly the internet, poses inherent risks. However, employing encryption during transit mitigates these vulnerabilities. We leverage multiple layers of encryption:
- VPN (Virtual Private Network): Establishes secure and encrypted connections between devices and networks, safeguarding data from interception or eavesdropping.
- TLS Protocol (Transport Layer Security): Provides a comprehensive security framework encompassing confidentiality, data integrity, and authentication. Unlike its predecessor SSL, TLS ensures robust protection against modern cyber threats.
- HTTPS (Hypertext Transfer Protocol Secure): Delivers data over the web in a secure and encrypted manner, ensuring the integrity and confidentiality of transmitted information.
Access Control: Gatekeeping Data Access
Effective access control mechanisms restrict data access to authorized users only. Implementing stringent access controls, coupled with multi-factor authentication, verifies the identity of users, thwarting unauthorized access attempts.
Vigilance Against Vulnerabilities
To fortify our defenses further, continuous vigilance against vulnerabilities is imperative. Regular software updates and patch management keep systems resilient against emerging threats, ensuring that potential entry points for attackers are swiftly fortified.
Data Resilience: Backing Up for Contingencies
Despite our best efforts, data breaches may occur. In such scenarios, robust data backup strategies become invaluable. Regularly backing up data ensures its resilience against loss or corruption, offering a lifeline in the event of a security incident.
Password Best Practices: Strengthening User Credentials
User passwords serve as the frontline defense against unauthorized access. Encouraging the adoption of complex, unique passwords and discouraging common, easily guessable ones fortifies this defense. Long, intricate passwords significantly increase the difficulty for attackers, deterring brute-force attacks and mitigating the risk of unauthorized access.
Data Integrity Monitoring
Monitoring data integrity is a potent security technique crucial for safeguarding business data against both known and unknown threats. By diligently scrutinizing the integrity of data, we fortify our defenses against unauthorized alterations and potential breaches. Let's delve into the intricacies of this process and its significance in bolstering cybersecurity measures.
Understanding Data Integrity Monitoring
Data integrity monitoring involves vigilant scrutiny of files, databases, and file systems to detect any unauthorized changes or alterations. This process entails the following steps:
-
Baseline Generation: Initially, we generate a cryptographic checksum for vulnerable data, establishing a baseline for comparison.
-
Regular Integrity Checks: Subsequently, we periodically recalculate the checksum of the same resources and compare them to the established baseline. Any deviations or alterations from the baseline trigger a security alert, indicating potential security breaches or unauthorized modifications.
Enhancing Security Vigilance
Monitoring data integrity enables us to detect various security threats, including malware infections within the operating system or other applications. By promptly identifying and addressing anomalies, we mitigate the risk of data breaches and ensure the integrity and confidentiality of sensitive information.
Resource Efficiency Considerations
While data integrity monitoring is a powerful security measure, it can be resource-intensive, particularly when dealing with large volumes of data. To optimize resource utilization, it's essential to focus monitoring efforts on data and files that are more vulnerable to cyber attacks. Key areas to prioritize include:
- User credentials and privileges
- Encryption key stores
- Operating system files
- Configuration files
- Application files
By directing resources efficiently towards monitoring these critical assets, organizations can effectively strengthen their cybersecurity posture while minimizing resource strain.
Conclusion
Key requirements for a payment system
- Reliability and correctness are critical.
- Fault-tolerant and highly available.
Key solution tools
- Redundancy
- Patterns for payment guarantees: Kafka, idempotency, and distributed systems.
- Strategies for retrying, timeouts, and fallbacks.